This is the first part of the SQLxD series. For your convenience you can find other parts using the links below :
Part 1 — XML Transformation
Part 2 — Grammar
Part 3 — Model and parsing XML
Part 4 — Selectors
Part 5 — Generating columns
Part 6 — FROM
Part 7 — WHERE with simple predicates
Part 8 — WHERE with joined predicates
Part 9 — WHERE and LIKE operator
Part 10 — WHERE and tests
Part 11 — JOINs
Part 12 — JOINs tests
Part 13 — Natural join
Part 14 — Grouping
Part 15 — Ordering
Part 16 — Aggregates
Part 17 — Tests for aggregates
Part 18 — Expressions
Part 19 — Expressions tests
Part 20 — Transformers
Part 21 — SELECT
Part 22 — Query parser
Part 23 — Query parser tests
Today we start new series in which we will implement basics of relational database management system processing XML documents. Engine will be implemented in C#, DQL queries will be parsed using IronPython, XML documents will be used as data sources, however, all queries will be working just like in ordinary SQL database. Let’s begin.
Table of Contents
Introduction
Whole series is more or less based on work I and Jakub Tokaj did in our thesis and publication covering the same area.
There are multiple tools and APIs for processing XML documents. One can use SAX parser, XQuery, XPath, LINQ to XML, or probably many other tools. All of them give access to all elements of document, however, we still need to be aware if its internal structure. On the other hand, we are used to relational databases, but processing XML in RDBMS is usually cumbersome. We need to explicitly define mappings, types, work with strange-looking paths. One might ask: is it possible to load XML document and treat it as a relational data source? Few years ago Jakub Wyrostek defended his master thesis presenting way of transforming XML documents into relational form, on which whole SQLxD database is based.
Transformation
General idea is to choose nodes from XML documents using multi-segment addressing (similar to two-segment or four-segment addressing in MS SQL), and transform them to rows of table. One node from XML document is flattened and mapped (with all its children) to one row, columns are created using attributes, children elements, and children text values. Nodes matching the same multi-segment addressing create the whole relation. Picture below presents the idea:
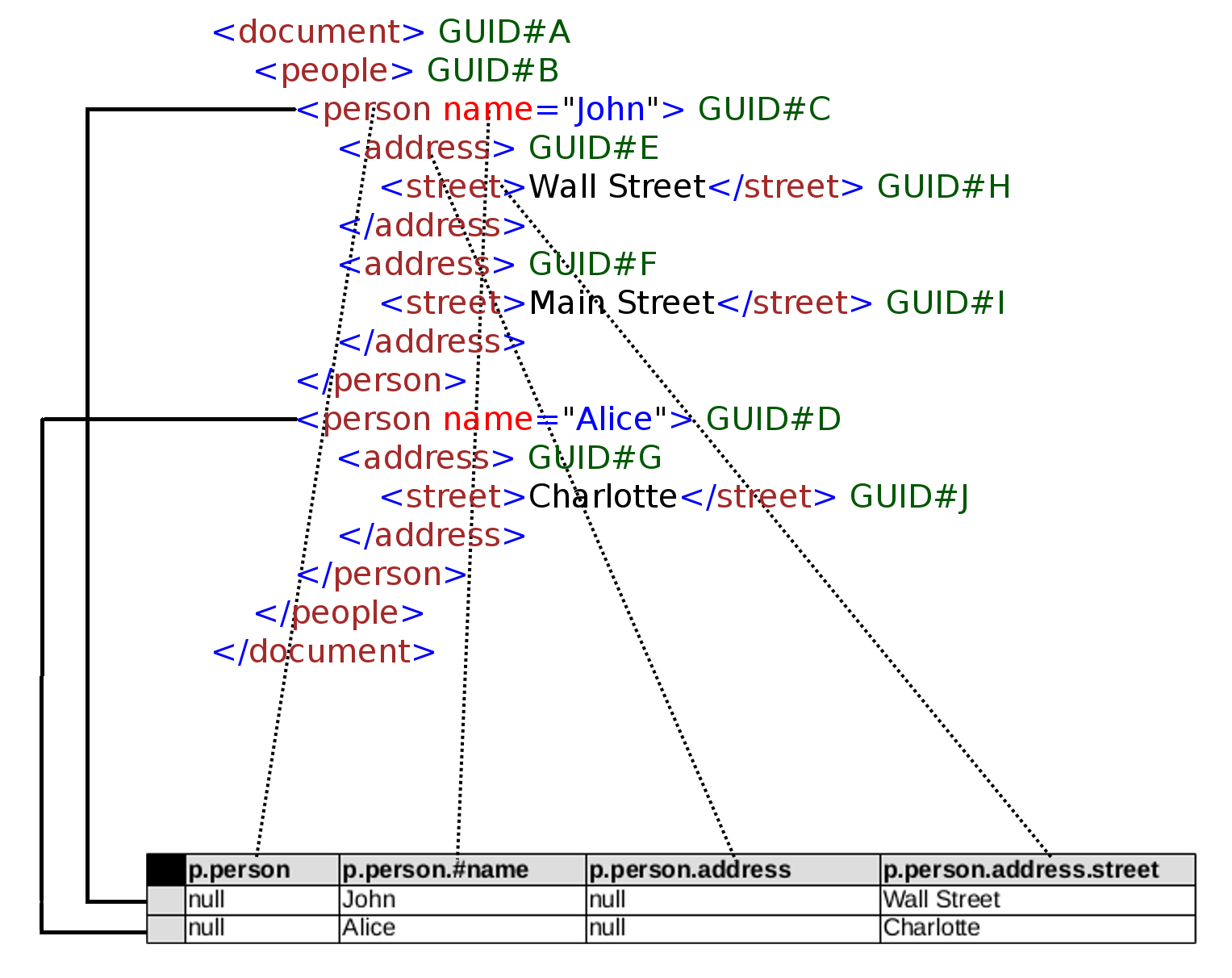
As we can see, we have two document.people.person nodes, so we end up with two rows. Each person node might have multiple address children, so we need to flatten them (and simply take first spotted value for each new path) in order to have flat structure representing tree node. Attributes are prefixed with #, missing values have nulls (as usual), nesting is signaled with dots (these are multi-segment identifiers).
Functions
Our engine will handle only DQL queries, which means that we will be able to load the document and perform SELECT queries. We will not focus on performance or safety, this is only a project for fun, so it will have little to no error handling.
We will handle joins, filtering, grouping, ordering, some aggregates, and (of course) projection. We will also introduce few useful methods working on strings (just to present how they can be integrated into engine). Almost all functions will work as in MS SQL, with only one exception — we will have very different notion of natural join.
Usually, natural join is just an inner join with implicit conditions defined by implementation. One database might join using keys, whereas other one might do it using all columns with matching names. In SQLxD natural join will indicate ancestor-descendant relationship. Having nodes document.people.person and document.people.person.address, by joining them we will end up with values extracted from the same subtree. Picture below presents this approach:
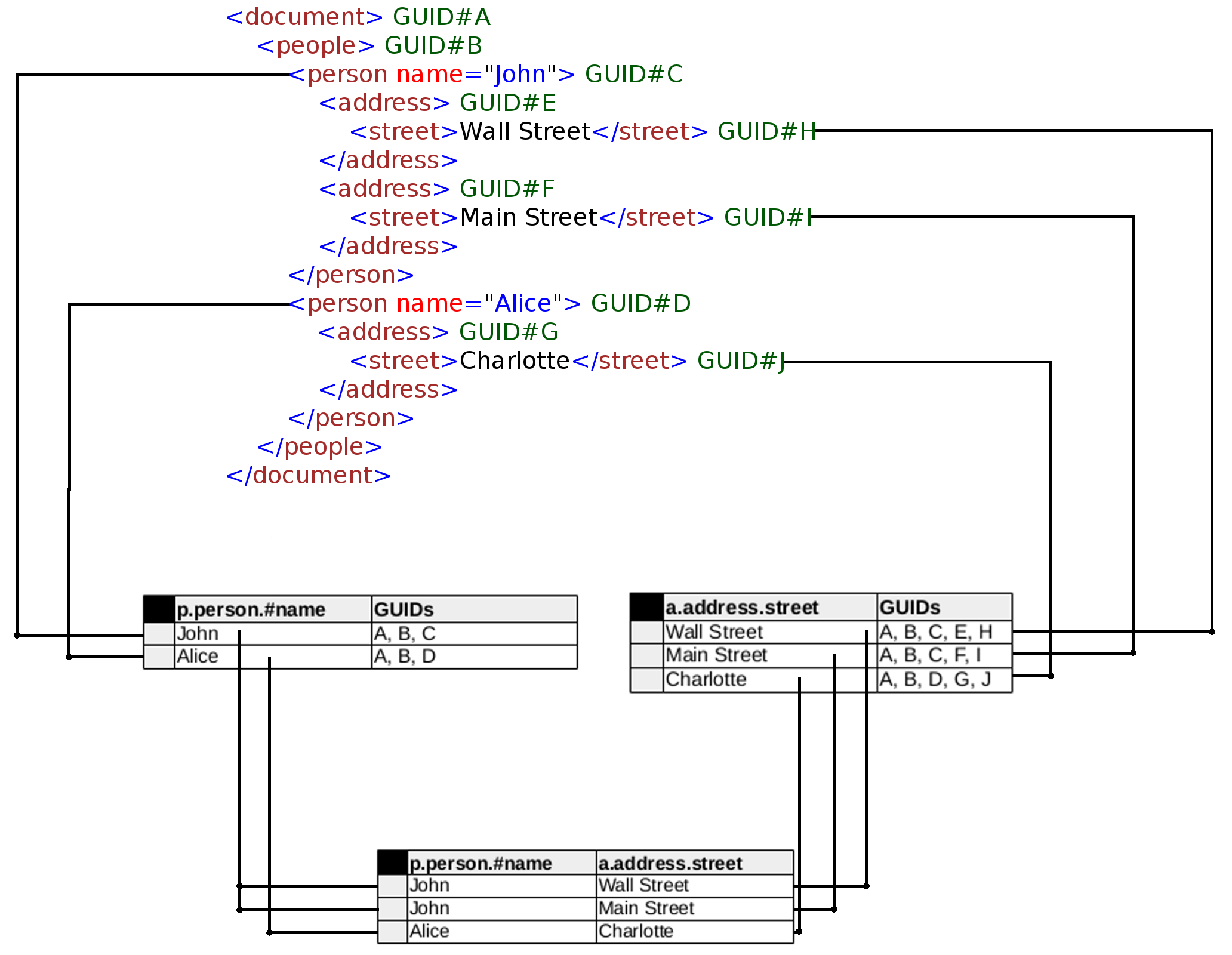
As you can see, John has two address subnodes, so we have two rows with matching street value.
Summary
In next part we will formally specify language grammar and describe how it differs from SQL-92.